
进程模型3-进程的栈
| 内核版本 | 架构 | 作者 | GitHub | CSDN |
|---|---|---|---|---|
| Linux-3.0.1 | armv7-A | Lux1206 |
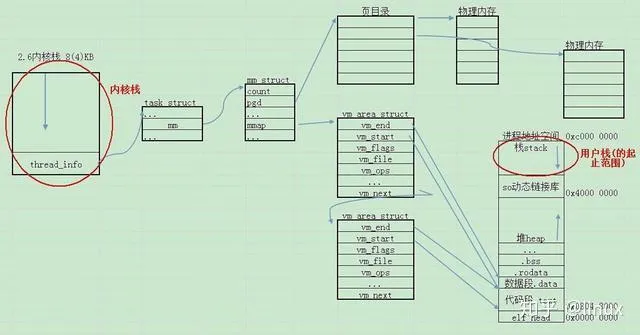
程序运行的必要条件之一就是拥有栈空间,用来存放运行过程中的临时变量、函数参数、函数返回值等数据,在 linux 中不论是内核进/线程还是用户进/线程都拥有独立的内核栈,用于在内核态运行程序,而只有用户进/线程才有自己的用户栈,只不过子线程是和主线程公用内存空间,他们的用户栈都在这片区域的不同位置。
进程内核栈
每个用户进程在运行的过程中都必然会通过到系统调用 SYSCALL 陷入内核。在进入内核之后,执行的内核代码所使用的栈并不是原先进程在用户空间中的栈,而是一个单独内核栈。对于 init_task 0 号进程来说,他的内核栈时通过全局变量的方式静态创建,位置位于 .data 段下的 ".data..init_task" 区域,其余的进/线程在通过 do_fork 创建时都会分配独立的内核栈。
内核栈的数据结构
/* 进程描述符 */
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped,进程状态 */
void *stack; /* 内核栈指针指向栈底位置,进程从用户空间进入内核空间时使用,指向union thread_union(struct thread_info)结构体 */
...
}
/* 内核栈联合体 */
union thread_union {
struct thread_info thread_info; /* 进程控制块 */
unsigned long stack[THREAD_SIZE/sizeof(long)]; /* 8K内核栈空间 */
};
内核栈的数据结构如上所示,是一个联合体结构,大小以最大成员为准,这种结构在 arm 满栈递减的栈模式下,stack[0] 相当于是栈底,** stack[THREAD_SIZE/sizeof(long)]** 相当于是栈顶,而 thread_info 控制块则是从栈底位置开始放置的进程控制块。找到进程内核栈就能找到进程控制块,进而找到进程描述符。
init_task进程内核栈创建
#define __init_task_data __attribute__((__section__(".data..init_task")))
union thread_union init_thread_union __init_task_data =
{ INIT_THREAD_INFO(init_task) };
init_task 进程的内核栈通过全局变量的方式静态创建,并通过__init_task_data 修饰将栈的位置放置在** .data** 段开始位置下的 ".data..init_task" 区域,在初始化 init_task 进程描述符时将内核栈指针设置为 init_task->stack = init_thread_union.thread_info,并在内核进入 start_kernel() 函数前在 head-common.S 中通过如下程序将 sp 指针指向** (&init_thread_union + THREAD_SIZE - 8) **的位置。
__INIT
__mmap_switched:
adr r3, __mmap_switched_data @将 __mmap_switched_data 地址赋值给r3
ldmia r3!, {r4, r5, r6, r7} @ 从__mmap_switched_data 将下的4 words 载入到r4~r7寄存器,r3地址会自动递增
...
ARM( ldmia r3, {r4, r5, r6, r7, sp}) @从ARM模式下继续将 5个words 载入到r4~r7和sp寄存器, 这里设置了0号进程的内核堆栈位置
THUMB( ldmia r3, {r4, r5, r6, r7} ) @THUMB模式下只能最多一次出栈到4个寄存器
THUMB( ldr sp, [r3, #16] )
...
b start_kernel @ 跳转到start_kernel开始进行内核初始化
ENDPROC(__mmap_switched)
.align 2
.type __mmap_switched_data, %object
__mmap_switched_data: @ 定义 __mmap_switched_data 数据结构
...
.long init_thread_union + THREAD_START_SP @ sp 设置到 (&init_thread_union + THREAD_SIZE - 8)的栈顶位置
.size __mmap_switched_data, . - __mmap_switched_data
其他进程内核栈创建
其他进/线程的内核栈都是在通过 do_fork 创建时申请的,并且通过 slab 分配器从 thread_info_cache 缓存池中分配出来,大小为 THREAD_SIZE,一般来说是2个页大小共 8K,最后在这 8K 空间上完成布局。
do_fork
└── copy_process
└── dup_task_struct
│ └── alloc_thread_info_node
└── copy_thread
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int node = tsk_fork_get_node(orig);
int err;
...
ti = alloc_thread_info_node(tsk, node);/* 申请新进程的内核栈 */
if (!ti) {
free_task_struct(tsk);
return NULL;
}
...
tsk->stack = ti; /* 将新的内核栈挂载到新进程描述符上 */
...
setup_thread_stack(tsk, orig); /* 把父进程内核栈下的进程控制块信息复制(浅拷贝)给新进程,并修改新进程控制块下的进程指针执行新进程 */
...
stackend = end_of_stack(tsk); /* 在内核栈底跳过 struct thread_info 位置后设置为STACK_END_MAGIC */
*stackend = STACK_END_MAGIC; /* for overflow detection */
...
return tsk;
...
return NULL;
}
static inline unsigned long *end_of_stack(struct task_struct *p)
{
/* 指向进程内核栈栈底,是 struct thread_info 之后的位置,因为struct thread_info放在了栈底需要跳过它 */
return (unsigned long *)(task_thread_info(p) + 1);
}
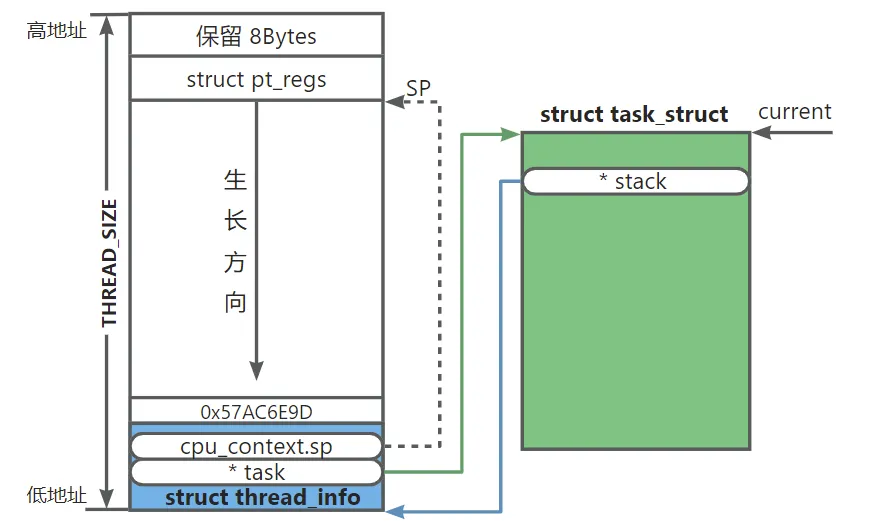
上面的代码可以看到每个进/线程都申请了新的内核栈,并且将内核栈挂载到新进/线程描述符的 *stack 上,然后将父进程的进程控制块信息通过浅拷贝的方式赋值到了新的进/线程控制块上,最后在栈底跳过进程控制块 struct thread_info 的位置上设置了 0x57AC6E9D 作为检查内存溢出的标志。
#define THREAD_START_SP (THREAD_SIZE - 8)
/* 在内核堆栈的栈顶以下开辟 8+pt_regs大小来存放压栈寄存器 */
#define task_pt_regs(p) \
((struct pt_regs *)(THREAD_START_SP + task_stack_page(p)) - 1)
int copy_thread(unsigned long clone_flags, unsigned long stack_start,
unsigned long stk_sz, struct task_struct *p, struct pt_regs *regs)
{
struct thread_info *thread = task_thread_info(p);
struct pt_regs *childregs = task_pt_regs(p);/* 获取子进程18个通用寄存器放置的位置(从内核栈顶-8开始),陷入内核时用户态的上下文信息保存在pt_regs数据结构中 */
*childregs = *regs; /* 通用寄存器保存到子进程栈顶-8位置,然后在进行差异性修改 */
childregs->ARM_r0 = 0; /* 后面用于子进程返回,也就是为什么fork后子进程返回0的原因 */
childregs->ARM_sp = stack_start;/* 什么作用??? */
memset(&thread->cpu_context, 0, sizeof(struct cpu_context_save));
thread->cpu_context.sp = (unsigned long)childregs; /* 进程控制块中的cpu上下文设置内核堆栈栈顶,指向用户空间上下文开始位置 */
thread->cpu_context.pc = (unsigned long)ret_from_fork;/* do_fork完成后的进程首次调度时从ret_from_fork开始 */
...
return 0;
}
在新进/线程内核栈创建好后会在内核栈的 栈顶-8 位置保存 struct pt_regs 通用寄存器,用于用户空间上下文切换时使用,整个内核栈在创建完成后布局如下:
进程用户栈
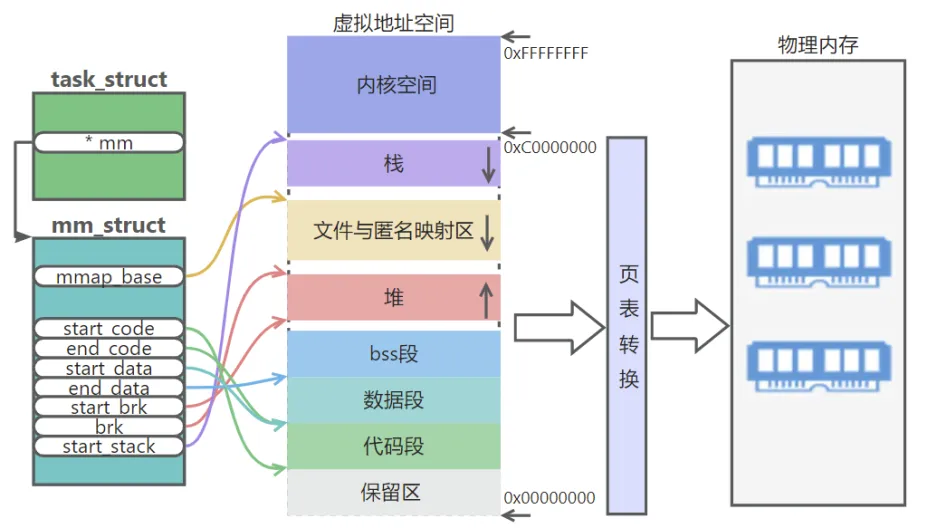
Linux 内核将 4G 字节的虚拟空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为内核空间,而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为用户空间。每个用户进程需要运行都必须先在用户进程的虚拟地址空间上完成程序所需各段的布局,而进程的用户栈就存在于用户进程的虚拟地址空间上。
进程用户栈和进程的虚拟地址空间息息相关,内存描述符如下:
struct task_struct {
...
/* mm: 进程的用户内存空间描述符(包括了用户栈),内核进程mm=NULL;
active_mm: 进程运行时所使用的内存描述符,普通进程mm=active_mm,内核进程的active_mm等于上一个进程的active_mm */
struct mm_struct *mm, *active_mm;
...
};
struct mm_struct {
...
unsigned long start_code, end_code, start_data, end_data;/* 代码段起始地址[start_code, end_code],数据段起始地址[start_data, end_data] */
unsigned long start_brk, brk, start_stack; /* 堆的起始地址[start_brk, brk],栈的开始地址 start_stack */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数起始地址[arg_start, arg_end],环境变量起始地址[env_start, env_end] */
...
};
用户进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,而对于 fork 后使用 execv 函数加载的情况,进程用户栈的大小被设置为** (128+4)K** 的大小,在 setup_arg_pages 中进行设置。 Linux 内核会根据入栈情况对栈区进行动态增长,这也是为什么栈只有 start_stack 的原因。但是并不是说栈区可以无限增长,它也有最大限制 _STK_LIM (一般为 8M)。当压栈耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。如果此时栈的总大小没有超过 8M栈会被加长,否则会导致栈溢出内核会产生 段错误(segmentation fault)。
需要说明的是用户子线程与主线程(进程)共用主线程的虚拟内存空间,在这个空间下为子线程分配独立的用户栈,由于子线程和主线程公用虚拟内存,所以他们的** mm->start_stack** 栈地址相同,意味着子线程栈的起始地址并没有存放在 mm 中,存在哪里有待后面分析。并且子线程的用户栈不能动态增长,一旦用尽就会出现问题。
中断栈
中断栈此处不进行介绍,后面在中断子系统中详细介绍。
🌀路西法 的CSDN博客拥有更多美文等你来读。
{kind=link}
{kind=link}